

OpenAI 表示,新版ChatGPT Images由最新的旗艦級影像生成模型驅動,不論是從零開始生成圖片,或是針對既有照片進行編輯,都能更貼近使用者原本的想法。此次更新的核心在於強化指令理解能力,讓模型能「只改使用者指定的部分」,並在多次編修過程中,維持光線、構圖與人物外貌的一致性,減少過去常見的失真問題。
以實際使用情境來看,當用戶只要求更換服裝、髮型或整體風格時,系統會保留臉部特徵與畫面氛圍,不會影響其他不相關元素,使修圖結果更自然,也更適合應用於造型試穿、風格轉換或視覺概念設計。OpenAI形容,這讓ChatGPT不只是「會畫圖」,而是能同時兼顧實用修圖與創意發想的影像工具。
在編輯能力方面,新模型也全面強化加、減、合成、混合與轉換等操作,能將不同人物或物件整合進同一畫面,或是逐步移除元素、轉換畫風,並在連續修改過程中維持整體一致性,避免畫面隨著調整次數增加而偏離原始設定。
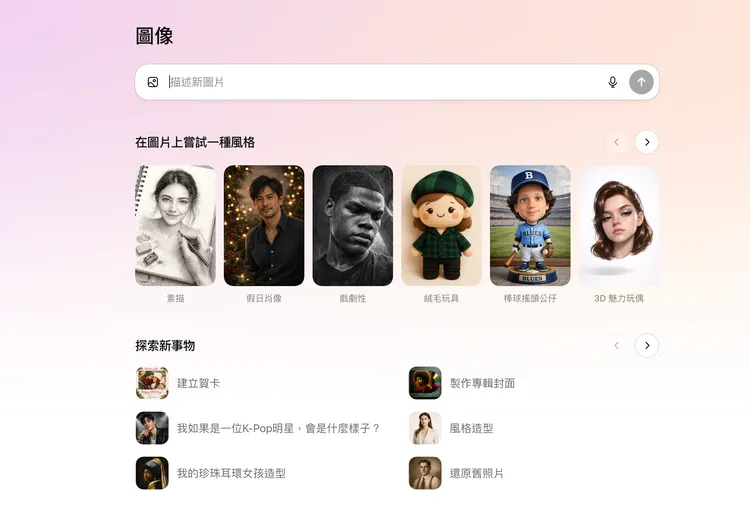
為了進一步降低使用門檻,OpenAI也同步在ChatGPT左側介面新增專屬的「圖像」分類,內建多種預設風格與靈感範本。即使使用者不知道該如何撰寫指令,也能直接點選範本快速開始創作,例如「建立賀卡」、「電影海報」,或是「如果我是一位 K-Pop 明星,會是什麼樣子」等情境式選項,ChatGPT便會自動生成對應風格的影像,並列出對應的提示指令,還能作為後續調整與延伸創作的起點。
另一項明顯升級,則是文字呈現能力。新版ChatGPT Images在小字與密集文字的生成表現上更為穩定,能處理資訊圖表、Markdown排版,甚至模擬報紙版面配置,對於製作簡報、教學素材或社群圖片的用戶而言,實用性明顯提升。
在開發者端,新模型也同步以GPT-Image-1.5名稱開放API使用,不僅在品牌識別、構圖與細節保留上更穩定,圖像生成與輸入成本也比前一代降低約20%。OpenAI指出,目前已有Wix、Canva、Figma、Shutterstock等平台導入相關應用,協助設計、行銷與電商團隊加快內容製作流程。
OpenAI也坦言,影像生成仍存在多人物一致性與跨語言細節等挑戰,未來仍有進一步改善空間。不過整體而言,這次ChatGPT Images的升級,已讓影像生成從過去偏向展示性質的功能,逐步走向更成熟、可實際投入工作與創作流程的工具。
根據記者實測,操作方式也相當簡單,只要在網頁版的ChatGPT中選擇左側的「圖像」分類後,上傳照片再自行輸入提示句或是參考提供的風格便會在數秒內生成圖片,接著還能進一步的輸入文字來做調整,在精準調整效果上的確是相當不錯。
新版ChatGPT Images已於今日起陸續向所有用戶開放,API也同步上線,顯示生成式AI在影像領域的競爭,正持續加速推進。
🟡 ChatGPT:https://chatgpt.com/images


 點擊閱讀下一則新聞
點擊閱讀下一則新聞



